Non basta la medicina, la lotta al COVID non può fare a meno dei numeri
Riceviamo e volentieri pubblichiamo da Marco Abatecola e Silvia Di Nicola.
La lotta alla pandemia si basa, senza dubbio, sulla ricerca e sull’impegno di migliaia di medici ed operatori sanitari che ogni giorno combattono il virus nelle corsie degli ospedali, ma non può prescindere da un sistema di dati e informazioni su cui deve fondarsi ogni scelta che politici ed esperti devono prendere – e stanno prendendo da sette mesi a questa parte – per contenere la diffusione del virus SARS-CoV-2 e portare il Paese fuori dall’emergenza sanitaria.
Il dibattito sulla reazione alla pandemia in atto e sulle strategie di contenimento del contagio si fonda invece, ad oggi, per lo più sulla reazione emotiva ai numeri che quotidianamente vengono diffusi. Lo scorso 30 ottobre, ad esempio, la diffusione del numero di 31.084 nuovi contagi ha spinto Governo, CTS e governatori di Regione a rimettere in discussione quanto deciso appena una settimana prima con il Dpcm del 24 ottobre 2020 per prendere ulteriori provvedimenti e più dure restrizioni alla libertà di circolazione delle persone con l’obiettivo, chiaramente, di limitare i contatti e quindi la trasmissione del virus.
L’incremento di 31.084 unità tra le persone risultate positive deriva da un numero abbastanza elevato di tamponi effettuati, pari a 215.085 per un indice di positività, su scala nazionale, del 14,45% (l’11 marzo 2020 risultava positivo il 98% dei campioni processati). Un numero di tamponi poderoso, senza dubbio, rispetto ai livelli che si registravano nella prima ondata dell’epidemia ma che non contiene informazioni chiave, che sarebbero invece necessarie non tanto per il contenimento dei nuovi focolai quanto per basare le strategie di risposta su dati in grado di far emergere, nel modo più accurato possibile, la situazione attuale della circolazione del virus sull’intera popolazione italiana.
Se si analizza l’ultimo dato disponibile elaborato dall’Istituto Superiore di Sanità emerge, ad esempio, che nel complesso dell’attività di rilevazione diagnostica dell’infezione è in costante calo la parte derivante dall’attività di tracing dei contatti – ormai intorno al 25,6% rispetto al 31,8% della precedente rilevazione – così come quella corrispondente all’impegno di screening – al 25,8% rispetto al 31,1% della precedente rilevazione – mentre aumentano i tamponi effettuati a seguito di comparsa di sintomi o altro (48,6%).
In sostanza il campione dei tamponi effettuati, essendo in minima parte legato ad una attività di screening, ha sempre più caratteristiche casuali e sempre meno valenza statistica. Vale, quindi, nella maggior parte dei casi come conferma di casi sospetti o probabili.
Figura 1

Figura 2

Elaborazioni su dati Task force COVID-19 del Dipartimento Malattie Infettive e Servizio di Informatica, Istituto Superiore di Sanità. Epidemia COVID-19, Aggiornamento nazionale
I dati dimostrano un progressivo deterioramento della capacità di programmazione dell’attività sistematica di accertamento diagnostico con tampone molecolare – conseguente a programmazione di screening o da attività di contact tracing – a favore invece delle componenti più episodiche, dovute o all’insorgenza di sintomatologia simil influenzale o alle scelte individuali per esigenze diverse (viaggio, lavoro, ecc.). Un problema non da poco se pensiamo che la gran parte dei casi di positività emersi sono asintomatici o paucisintomatici, potendo quindi assumere che molti altri nelle medesime condizioni sfuggano dal sistema di rilevazione, non avendo sintomi o condizioni di esposizione al rischio. Anche perché il rischio contatto che spinge il soggetto ad effettuare eventualmente il tampone, anche in assenza di sintomatologia, è strettamente legato alla definizione di contatto stretto. “Contatto stretto” per il Ministero della Salute è:
- una persona che vive nella stessa abitazione di un caso COVID-19
- una persona che ha avuto un contatto fisico con un caso confermato
- una persona che ha avuto un contatto diretto con le secrezioni di un caso di COVID-19
- una persona che ha avuto un contatto faccia a faccia con un caso confermato, a distanza minore di 2 metri e per più di 15 minuti
- una persona che si è trovata in un ambiente chiuso per più di 15 minuti con un caso di COVID-19 a distanza minore di due metri.
Al di fuori di questi casi, l’attività di tracciamento non viene avviata e l’eventuale tampone di controllo è quindi rimesso alla libera volontà del soggetto o alla decisione del Medico di Medicina Generale nel caso venisse attivato pur in assenza di sintomatologia specifica.
Figura 3
% di casi di COVID-19 segnalati in Italia per stato clinico attuale e classe di età
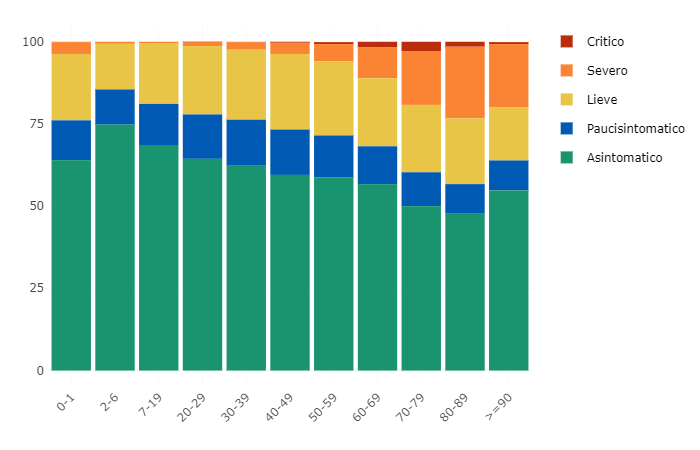
Dati: Istituto Superiore di Sanità – EpiCentro
Peraltro, le indicazioni relative alla diagnosi di laboratorio, emesse dalla Direzione Generale della Prevenzione Sanitaria del Ministero della Salute, prevedono che i laboratori di riferimento regionali inviino un numero rappresentativo di campioni clinici dei test effettuati al laboratorio di riferimento nazionale in ISS “al fine di monitorare l’epidemiologia molecolare di SARS-CoV-2”. Ma tali campioni sono evidentemente rappresentativi del totale dei tamponi effettuati ma non anche della popolazione di riferimento. Pertanto, il monitoraggio dell’epidemia risulta basato su un campione fortemente condizionato e non su sottoinsiemi di unità statistiche da osservare per una rilevazione campionaria del fenomeno, stimandone la diffusione ed il comportamento.
Chiaramente, se le attuali linee guida sugli accertamenti diagnostici dell’infezione – volendosi qui limitare a quella effettuata con tampone nasofaringeo come test molecolare basato sull’identificazione di RNA virale – sono di importanza fondamentale per l’individuazione dei focolai e per l’identificazione dei contatti a rischio o sospetti, altrettanto non può dirsi per la loro efficacia come sistema di rilevazione, per approssimazione, dell’incidenza del contagio sulla popolazione italiana totale e sulle singole fasce e classi che la compongono. Sia ai fini dell’individuazione delle migliori politiche di contrasto e contenimento che in termini predittivi sfruttando la storicità del dato e le proiezioni che consente.
Le informazioni fino ad ora fornite in merito alla diffusione del virus sono, infatti, riconducibili principalmente a soggetti che manifestano sintomi o soggetti maggiormente esposti al rischio di contagio, con bassa incidenza dunque degli asintomatici o paucisintomatici sulla reale consistenza delle persone contagiate. Le valutazioni sull’andamento dei contagi sono pertanto basate su dati incerti, correlati più che altro alla numerosità dei tamponi effettuati giornalmente, e non necessariamente rappresentativi dei numeri reali della circolazione del virus tra la popolazione residente.
Anche il tentativo fatto con il protocollo InfluNet & CovidNet non ha risposto in pieno alla necessità di creare una base dati statisticamente indicativa, essendo basato sulle segnalazioni di MMG e Pediatri – a copertura di circa il 4% della popolazione – delle sindromi simili influenzali (ILI) considerando almeno uno tra i seguenti sintomi generali:
- febbre o febbricola
- Malessere/spossatezza
- Mal di testa
- Dolori muscolari
e, almeno uno tra i seguenti sintomi respiratori:
- tosse
- mal di gola
- respiro affannoso
Una raccolta dati, quindi, non focalizzata sulla presenza del virus SARS-CoV-2 ma sull’emergere di sintomatologie genericamente influenzali e distinguibili soltanto, tra loro, attraverso tampone e con ricerca specifica del virus, anche con test multiplex di real-time RT-PCR in grado simultaneamente di rilevare e differenziare influenza A, B e SARS-CoV-2.
Perché si arrivi ad avere un datasets statisticamente rilevante non basta, quindi, la rete InfluNet – o, come qualcuno pure ha proposto, i dati rilevabili dall’uso dell’app Immuni ad oggi utilizzabili per la sola attività di tracing specifico – e neanche analizzare il numero dei tamponi quotidianamente effettuati (o, meglio, una parte di essi) ma occorre clusterizzare la popolazione italiana procedendo poi al campionamento statistico dei singoli sottogruppi individuati. A quel punto, ogni campione potrà essere periodicamente sottoposto a test diagnostico potendone mappare il comportamento rispetto alla diffusione del virus e riuscendo così ad avere una stima accurata del suo andamento, tempo per tempo, sulla popolazione residente.
In altre parole, si sarebbe già dovuti arrivare ad una rilevazione statistica vera, da effettuarsi attraverso la costruzione di un campione rappresentativo della popolazione italiana, estratto selezionando per ogni regione un campione casuale di unità, con stratificazione proporzionale per genere e classi di età (superiori a 18 anni). Ovviamente la numerosità del campione dipende dall’intervallo e dal livello di confidenza che si ritiene accettabile. Al fine di ottenere stime affidabili, la base di campionamento, fissato l’errore statistico all’1%, potrebbe essere costituita da circa 17.000 unità di osservazione, che si riducono a poco meno di 10.000 potendo ritenere accettabile il ricorso ad un livello di confidenza che passa dal 99% al 95%.
Tabella 1
| PREV ATTESA 0.5 – LIVELLO CONF 0.99 | |||
| Prevalenza attesa | 0,5 | 0,5 | 0,5 |
| Intervallo confidenza | 0,01 | 0,02 | 0,03 |
| Livello confidenza | 0,99 | 0,99 | 0,99 |
| Numerosità campione | 16.636 | 4.160 | 1.849 |
| PREV ATTESA 0.5 – LIVELLO CONF 0.95 | |||
| Prevalenza attesa | 0,5 | 0,5 | 0,5 |
| Intervallo confidenza | 0,01 | 0,02 | 0,03 |
| Livello confidenza | 0,95 | 0,95 | 0,95 |
| Numerosità campione | 9.602 | 2.401 | 1.067 |
La popolazione così selezionata verrebbe sottoposta a tamponi periodici, o a test sierologici per comprendere anche lo sviluppo di anticorpi anti SARS CoV-2, da ripetersi con cadenza quindicinale e per il periodo di tempo ritenuto necessario per il monitoraggio dell’evoluzione dell’epidemia, finalizzati allo svolgimento di un’analisi campionaria continuativa della diffusione del virus su una sub-popolazione selezionata tra soggetti sani e positivi al Covid-19.
In considerazione della valenza anche sociale dell’indagine, dovrebbe essere previsto l’obbligo di partecipazione alla rilevazione (come già accade per altri tipi di rilevazione statistica), al fine di evitare la scarsa copertura del campione o un’autoselezione dei partecipanti che possa compromettere la rappresentatività della popolazione d’interesse.
Attraverso un sistema di sorveglianza così sviluppato, si realizzerebbe un monitoraggio nel tempo sullo stato infettivo della popolazione mediante il quale ottenere stime statisticamente affidabili sulla diffusione del virus, calcolare con maggiore attendibilità il tasso di letalità da Covid-19 e altri parametri epidemiologici nonché valutare l’effetto di eventuali misure di contenimento adottate.
Mediante il ricorso ad un campione rappresentativo sarebbe inoltre possibile effettuare elaborazioni utili a costituire un sistema informativo completo sulle caratteristiche socio demografiche dei contagiati e sulla distribuzione territoriale dei soggetti affetti da Covid-19.
Anche tenuto conto del forte incremento di contagi registrati negli ultimi giorni, appare dunque sempre più evidente l’importanza di dotarsi di uno strumento di monitoraggio che – attraverso una procedura campionaria rigorosa – rappresenti un cruscotto fondamentale che consenta di assegnare ai risultati osservati un certo grado probabilistico di affidabilità e che permetta così di fare inferenza sull’intera popolazione.
Provvedimenti che incidono sulle libertà di movimento di sessanta milioni di persone non possono essere condizionati soltanto dai numeri dei contagi quotidianamente comunicati, cedendo alla paura, ma devono necessariamente partire da qui, da numeri e dati che aiutino esperti e politica, guidandone le scelte per superare una crisi sanitaria ed economica senza precedenti.
Marco Abatecola è Responsabile Settore Welfare Pubblico e Privato Confcommercio – Imprese per l’Italia. Silvia Di Nicola è Settore Welfare Pubblico e Privato Confcommercio – Imprese per l’Italia.
You may also like